Generative artificial intelligence (GenAI) has drawn attention from multiple fields due to its affordances. Since its emergence, this technology has remarkably permeated our daily activities in unimaginable ways, from customer service to medical diagnoses through chatbots (Miao et al., 2021). Nevertheless, GenAI, as a fast-growing technology, still raises doubts, questions, and concerns about its unprecedented performance (Gillani et al., 2023).
GenAI, rooted in fields such as artificial intelligence and machine learning, has raised concerns regarding privacy and ethical issues. According to a report of the European Commission (2020), GenAI may offer opaque decision-making, foster gender-based inequalities, be used for criminal purposes, and even intrude into our private lives. Of special relevance is how this technology utilizes vast amounts of information in the public domain and users’ data to build its models. Therefore, GenAI providers are legally obliged to inform users about the rules governing their services. However, the documents, terms of service and privacy policy, contain multiple discourses and rhetorical devices that prevent users from thoroughly understanding what rules they agree to.
This study employed critical discourse analysis to answer the following questions:
What discourses do GenAI providers use in the construction of the terms of service and privacy policy documents?
What language features do GenAI providers utilize to obscure the rules of their services?
This study employed critical discourse analysis (CDA) to examine the discourses and linguistic features utilized in the construction of the terms of service and privacy policy documents of two GenAI providers, OpenAI and Google. In CDA, text can take the form of written and spoken language, and images, or a combination of the three (Wooffitt, 2005), making this approach suitable to analyze discourse regardless of its form.
Two data sets were generated per company. These were extracted directly from their websites as they are in the public domain. The analysis process encompassed three analysis cycles (see Figure 1).
Figure 1
Analysis cycles
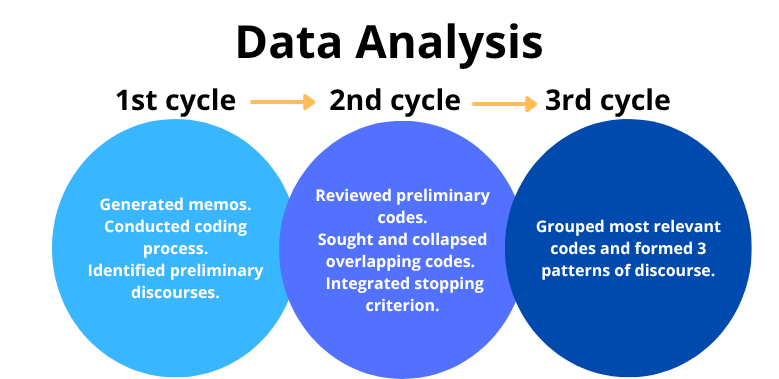
First, a preliminary data analysis (Grbich, 2013) was conducted to familiarize with the data sets and conduct a preliminary coding process. This cycle aimed to examine thoroughly recurrent discourses and language features. In the next cycle, the identified codes were iteratively reviewed to avoid overlapping elements. The last iteration focused on grouping the most relevant codes into three patterns of discourse (see Table 1) by considering their relevance for the study. MAXQDA qualitative analysis software version 24.4. supported the analysis process enabling me to classify and examine data more efficiently, generate visualizations of coded data (see Figure 2), and select relevant data.
Figure 2
Visualization of coded data
The findings were organized into three patterns of discourse (see Table 1). These discourses were supported by original excerpts withdrawn from the documents.
Table 1
Patterns of discourse
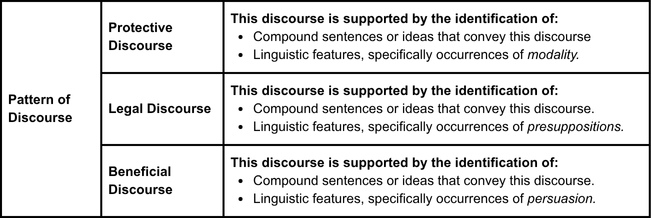
This discourse is characterized by excerpts in which the authors of the documents inform users that the terms they agree to protect both their companies’ interests and “associated software applications.” However, the authors fail to include further information about third parties, simplifying all the partnerships in the word, “services” and “affiliates.” (see excerpts 1 and 2). This leaves users with no choice but to guess how many companies are protected by these terms of service.
Excerpt 1. Terms of service – OpenAI – paragraph 1, section “terms of service.”
These Terms of Use apply to your use of ChatGPT, DALL·E, and OpenAI’s other services for individuals, along with any associated software applications and websites (all together, “Services”)
Excerpt 2. Terms of service – Google – section “your relationship with Google”
These terms help define the relationship between you and Google. When we speak of Google, we, us, and our, we mean Google LLC and its affiliates.
Other samples supporting this discourse utilized modal verbs (e.g., may, can, and must). Modality is divided into epistemic and deontic types. While epistemic modality denotes the likelihood that an event will occur, deontic modality conveys obligation. Modal verbs appear frequently, with “may” being the most prominent. According to Richards and Schmidt (2002), “may” conveys possibility or likelihood. This modal verb appears constantly across the documents to convey uncertainty and probability, benefiting the companies’ own interests. For instance, while the excerpt 3 depicts an instance of how the authors used “may” to justify the utilization of “aggregate information and analytics”, excerpt 4 displays how they used the modal verb “must” to oblige users to agree to the terms.
Excerpt 3. Privacy policy – OpenAI – paragraph 6, section “personal information we collect.”
The companies that host our social media pages may provide us with aggregate information and analytics about our social media activity.
Excerpt 4. Terms of service – OpenAI – paragraph 2, section “using our services.”
In using our services, you must comply with all applicable laws as well as our Sharing & Publication Policy, Usage Policies, and any other documentation, guidelines, or policies we make available to you.
Another discourse is related to legal discourse, which is characterized by the use of technical terminology and presuppositions. In excerpt 5, the authors employed specific phrases to persuade users and convey that they are supported by a legal system. Phrases such as “to provide our service to you ” and “complying with our legal obligations” are used consistently and strategically positioned in the documents to legitimize the retention of information.
Excerpt 5. Privacy policy – OpenAI – Paragraph 2, section “security and retention.”
We’ll retain your Personal Information for only as long as we need in order to provide our Service to you, or for other legitimate business purposes such as resolving disputes…or complying with our legal obligations…How long we retain Personal Information will depend on a number of factors, such as…
Additionally, presuppositions were recurrently utilized by the authors. In linguistics, a presupposition is “what a writer or speaker assumes that the receiver of the message already knows” (Richards & Schmidt, 2002, p. 416). In excerpt 6, the authors assumed that every user knows what “output” and “model” mean. Furthermore, they do not include a definition of those words, preventing users with poor digital or AI literacy from understanding the terms they agree to.
Excerpt 6. Terms of service – OpenAI – bullet point 6, section “what you cannot do.”
You may not use our Services for any illegal, harmful, or...For instance, you may not: use output to develop models that compete with OpenAI software.
This discourse is characterized by the way the authors of the documents write to convey that their services are intended to benefit all of humanity (see excerpt 7), thereby influencing users' decision-making. Similarly, this discourse is utilized to justify the use of users’ data, stating that GenAI providers use that information to improve their services and user experience (see excerpt 8).
Excerpt 7. Privacy policy – OpenAI – paragraph 1, section Who we are.
Our mission is to ensure that artificial general intelligence benefits all of humanity.
Excerpt 8. Privacy policy – Google – paragraph 6. section Why Google collects data.
We also use your information to ensure our services are working as intended…And we use your information to make improvements to our services, for example, understanding which search terms are most frequently misspelled helps us improve spell-check features...
Moreover, persuasive techniques are employed in different sections of the documents. Persuasion is a rhetorical device to convince others to agree with our facts, share our values, and accept our arguments (Gass & Seiter, 2018). These are used by appealing to the audience's emotions, fears, desires, etc. Excerpt 9 depicts an instance where the authors inform users that if they refuse to share their content to train their models, their services may be “limited” to address their specific needs.
Excerpt 9. Terms of service – OpenAI – paragraph 1, section Opt out.
If you do not want us to use your Content to train our models, you can opt out…Please note that in some cases this may limit the ability of our Services to better address your specific use case.
Similarly, excerpt 10 shows how the authors included a persuasive narrative and capitalization, highlighting the great services the company offers. This is before informing users that their services are subject to potential failure.
Excerpt 10. Terms of service – Google – paragraph 2, section “warranty disclaimer.”
WE BUILT OUR REPUTATION ON PROVIDING USEFUL, RELIABLE SERVICES LIKE GOOGLE SEARCH AND MAPS…HOWEVER, FOR LEGAL PURPOSES, WE OFFER OUR SERVICES WITHOUT WARRANTIES UNLESS EXPLICITLY STATED IN OUR SERVICE-SPECIFIC ADDITIONAL TERMS.
The authors of the documents, terms of use and privacy policies of OpenAI and Google, use a wide range of discourses, rhetorical devices, and linguistic features for different purposes, as evidenced above. They make sure to include statements that extend the application of their rules to their affiliates and third parties, leaving no room for complaints or gains in favor of users. Additionally, they used linguistic features either to avoid liability for the output of their GenAI or convince users to share their personal information and content. The paradox here is that when users agree to the terms of service and privacy policy, they not only waive their rights to have control over their personal information and what it is done with it, but also over the authorship of input they make in the form of text, image, or audio. Any material that users use while using their services could be used for building their models. Yet, the output material (e.g., the material or content created by GenAI) belongs to the user. In other words, the user is responsible for any wrongdoing connected to the output material.
This paper does not seek to criticize GenAI providers' practices regarding the rules governing their services. On the contrary, it aims to demand that GenAI providers use clearer and less ambiguous language when informing users of their rights. There are still many users who lack proficiency in digital or AI literacy, preventing them from understanding the implications of agreeing to the terms of use these companies put forward.
Many concerns remain regarding the real purpose of the documents. Ordinary users of GenAI do not know specifically what the owners of this technology are doing with their personal information and content. Thus, it is imperative to create more awareness regarding emergent technologies through the deployment of training programs on new literacies (e.g., media literacy, multicultural literacy, digital literacy, AI literacy) needed in a rapidly changing world (Coiro et al., 2014).
Additionally, it is essential to fight the technochauvinist bubble (Broussard, 2019) in which we are immersed. This term is used to describe the false idea that digital technologies, like AI, are the solution for everything, preventing users from taking the time to identify the advantages and disadvantages of using new technologies and make informed decisions about their usage.