Storing and sharing data securely has become essential for current researchers and those desiring to enter the field. Securely sharing data, or making it more open, increases transparency, reduces redundancy, and enables other researchers to confirm and refine study methods and findings (Dijkers, 2019; Eaker, 2020). Managing large datasets poses challenges for researchers, and researchers are increasingly turning to data science and artificial intelligence (AI/ML) tools to harness capabilities for expansive processing and analysis (Miksa et al., 2019). However, to harness AI/ML tools for data analysis, researchers need to prepare data to be computer-read and interpreted while also thoughtfully addressing the extent to which data will be made openly available for research community access. These considerations are formalized through developing a research project data management plan.
Data management plans have become an expected component of external funding applications (National Institutes of Health, 2020; Williams et al., 2017). As part of the more significant open science movement, researcher competency in data sharing can foster “a scientific ecosystem in which research gains increased visibility, is shared more efficiently, and is performed with enhanced research integrity” (Open Science Skills Working Group of the European Commission, 2017, p. 5). That is why funding agencies and the research community have recognized the educational need for courses and other designed learning experiences in research data management (Gargiulo et al., 2021; Majid et al., 2018; Palsdottir, 2021).
While the need for instruction on data management planning has been identified more broadly,
Designing the course brought together individuals with expertise in instructional design, computer science, population health, research training, sociology, ethics, and data science. To understand the scope of content for the course, the team explored current literature describing data collection, storage, preservation, and availability; data management planning; defining metadata using common standards and practices; and maintaining data provenance [the historical information related to the handling of the data] (Demchenko et al., 2017; Wolff et al., 2021). The FAIR principles are the preferred guidance for deciding where and how data can be placed to support access, reuse, and analysis (Bezuidenhout, 2021; Higman et al., 2019; Wilkinson et al., 2016). The acronym FAIR stands for findability, accessibility, interoperability, and reusability. Infusing FAIR into data management practices enables “the machine knows what we mean,” referring to machine actionability; this makes it possible for machines to read and process the data successfully (Jacobsen et al., 2020, p. 13). The four FAIR foundational principles contain 15 FAIR guiding principles that provide greater specificity to support interpretation and implementation by individual stakeholder communities. The FAIR guidance encompasses metadata schemes, structured vocabularies for annotations, and data repository storage and access that support greater efficiency and effectiveness of data use through computer-executed automation of data indexing, retrieval, and analysis (Boeckhout et al., 2018; Persaud et al., 2021; Wise et al., 2019). The framework provides direction for communities (such as those from particular specialty areas) to evaluate their metadata practices, determine needed improvements, and adapt the implementation of the FAIR principles to their needs.
Synthesizing the performance needs and content demands, the team articulated the following four learning goals for the course:
The team analyzed the goal statements further and gathered information resources about the associated concepts and skills for each goal statement. More specific learning objective statements were then drafted and refined as the curriculum developed. For example, the learning objectives connected to goal 4 are as follows:
4.1.1 Learners will identify the components of rich metadata.
4.1.2 Learners will explain the purpose of a persistent identifier.
4.1.3 Learners will register meta(data) in a searchable source.
4.2.1 Learners will explain the importance of open, free, and universally implementable protocols.
4.2.2 Learners will identify the types of data access levels.
4.2.3 Learners will apply the principles of accessibility to a dataset.
4.3.1 Learners will explain the term “qualified references.”
4.3.2 Learners will create metadata that includes FAIR vocabularies.
4.3.3 Learners will find controlled vocabularies associated with terms in their fields of study.
4.4.1 Learners will describe good data reusability practices.
4.4.2 Learners will create detailed provenance for a given dataset.
4.4.3 Learners will list the minimum metadata requirements.
The team gathered design precedents that could provide insights into potential course formats and instructional approaches to teach FAIR principles in data management planning (Boling, 2021). As a relatively new training area, we found varied training approaches ranging from lecture-based sessions to hands-on workshops involving practice with data set labeling and storage. The utility of the design precedents for our instructional design was that they provided the team with ideas for content breadth, sequencing, activities, and organizational structure that we would later use in developing our course. We noted how prior courses have prioritized instructional design strategies that build upon theoretical discussions through activity opportunities for implementing FAIR principles in real-world research contexts.
One design precedent came from a collaborative group of about 40 individuals from the FAIRsFAIR - Fostering Fair Data Practices in Europe project, in which they produced a handbook for college educators (Engelhardt et al., 2022). In a section on “Teaching and Training Designs for FAIR,” the authors acknowledge the diverse learning needs of professionals in this space and suggest considering a variety of training format possibilities –
FAIR training could be delivered as part of a formal course, part of a training or promotional event, or it can be embedded in managerial processes (e.g., grant application support, ethical review process, basic training for new affiliate researchers, etc.). It could also be a lecture, a workshop, a series of events, an online course, self-learning materials, or training interventions. (p. 37)
The handbook writers specifically articulated each training format type’s pros and cons regarding the FAIR content and contextualized the format decision considering the training goals, available resources, and anticipated constraints. For example, FAIR training “events” provide advantages of networking opportunities and promotion of open data science. However, they tend not to provide enough time to delve deeply into this content.
FAIR (2022) also offers an example of a self-learning material – a question-based online tool called “FAIR-Aware.” The tool is designed for users who have a particular dataset and are working to prepare it for uploading to a data repository. Available in English and French, the tool presents users with ten self-assessment questions that generate targeted guidance texts in the FAIR areas they most need. It also provides a glossary of commonly used FAIR-related terms. For trainers, it offers capabilities for downloading learner self-assessment results and utilizing analysis templates to provide follow-up feedback and support to learners.
We found workshops and courses to be another recognized approach for the FAIR content. For example, the German National Library of Science and Technology (Technische Informationbibliothek [TIB]) conducted a week-long in-person workshop that included didactic presentations of the content via lectures ranging from 17 minutes to just under two hours and hands-on coding sessions using practice materials in various STEM disciplines (Leinweber et al., 2018). The scope of content was organized across the five days as (a) FAIR introduction and findability, (b) accessibility, (c) interoperability, (d) reusability, and (e) wrap-up. The lectures were recorded and released as a nine-part series available under Creative Commons licensing for free access. The hands-on coding sessions align with case-based learning (CBL) techniques, which have been used in biomedical education to enable professional learners to consider target objectives within real-world scenarios and resources (Greenberg-Worisek et al., 2019). The training immerses learners in the content and facilitates knowledge development through immersive and meaningful learning experiences.
The team also considered design precedents from their own experiences. One author with previous experience teaching an undergraduate course for pre-service teachers described some of the hands-on activity strategies she has used for engaging learners with new vocabulary. Card sort is one such activity in which students are provided with a stack of cards or post-it sticky notes and a list of terms. Working in small groups of 2-3, students write the terms on the cards and then ideate categories and ways to create groups of terms. Following the sorting, groups share their category headings, organizational approaches, and relationships that they view among the terms. Think-Pair-Share is another activity strategy this author has used to prompt learners to consider their prior knowledge and experiences with target concepts and socially engage in conversation with a classmate about their thoughts.
Two other authors have built prior online, on-demand short courses on the Coursera and Blackboard platforms, including courses about instructional technologies for teachers, COVID-19 contact tracing, and value-based care. They reflected on structural aspects of the materials, including format types, lengths, graphical elements, interactive components, assessment approaches, and connections to real-world applications. For example, the courses largely present the content through short (about 3-7 minutes) videos that were edited to appear professional and unified across each course. The videos incorporate intro/outro audio/video sequences, on-screen text to reinforce key terms, diagrams that illustrate relationships between concepts, and high-quality stock and original photographs. Videos and activities in these courses were often grouped into modules that could be completed in about 1-2 hours. Embedded video questions and closed-response quiz items were used to assess learner recall of concepts. Several of the courses culminated in peer-graded assignments that prompted learners to apply the target skills in the development of a written submission that would then be reviewed by several of their course mates. The peer-graded assignment instructions were highly detailed, with specific instructions on what the learners were to produce and how peer graders should score and provide feedback on their classmates’ work.
We then conducted a learner analysis study with a cohort of target learners from OHD-PRIDE. Learner analysis can inform the appropriateness and feasibility of the intended training for the target audience (Agic et al., 2023; Dick et al., 2015). We constructed a learner analysis survey instrument to gather data on learners' demographics, prior familiarity with FAIR, and learning preferences that could be used to inform the instructional design project plan. The intention of gathering information about learning preferences was to understand how learners might desire content representations, learning activity options, and assessment formats, as was found useful by Rohani et al. (2024) in the development of health data science education programs. The instrument underwent expert review for content validity by two mentors from the program, and review feedback was used to simplify and clarify the items. The resulting instrument consists of demographic, FAIR principles knowledge, and learning preferences items (see Appendix A). We attended a January 2022 cohort meeting and discussed the educational need in light of upcoming federal grant proposal expectations for implementing FAIR principles into data management planning. Following Institutional Review Board approval, an invitation to participate in the study was distributed to members of the program cohort.
All six cohort members consented in writing to participate and completed the survey via Qualtrics XMTM online survey software (100% response rate). Respondents included three males and three females, primarily in the age range of 35-44 years, with one individual younger and one older than that range. Five respondents described themselves as Black or African American, and one as Hispanic/Latino. All respondents indicated that their primary research area was obesity health disparities. The collected survey data were analyzed using descriptive statistics for the items in the FAIR principles knowledge and learning preferences sections, and summary themes were identified and discussed within the research team to identify connections to considerations for the course design.
Respondents indicated minimal prior awareness of the FAIR principles overall. Figure 1 illustrates the target learners’ preferences for learning about using FAIR. The average ratings were similar (Agree) for three of the four preferred learning methods: visually, such as viewing diagrams, videos, or presentations; aurally, such as listening to audio recordings or participating in group discussions; and physically, such as participating in hands-on activities. The fourth option, reading and writing, was indicated as their least preferable.
Figure 1
Target Learner Preferences for Learning about FAIR
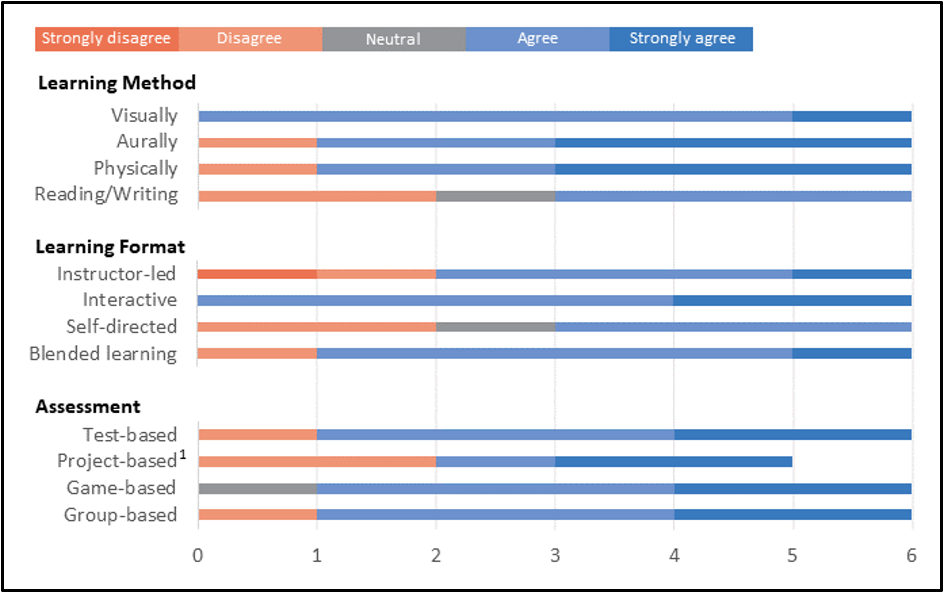
1Note: There was one missing response in the project-based assessment item.
The target learners were divided in their views about the preferred learning format for the FAIR content. For instance, four respondents agreed and strongly agreed that instructor-led/traditional training would be preferable, while the other two disagreed and strongly disagreed. Responses regarding self-directed learning (e.g., critical reflection, mind mapping, independent learning activities) were mixed. This category yielded slightly lower ratings, with three agreeing, two disagreeing, and one indicating neutral. The one format that respondents unanimously preferred was interactive training activities, such as group activities, games, and simulation. Blended learning was the second most preferred format.
Regarding preferred assessment formats, interactive game-based assessments were preferred mainly, followed by group-based assessments. Respondents had mixed views on the project-based format option. The test-based assessments category was the least preferred assessment format. An additional assessment format of the "adaptive learning method" was suggested in the "Other" option.
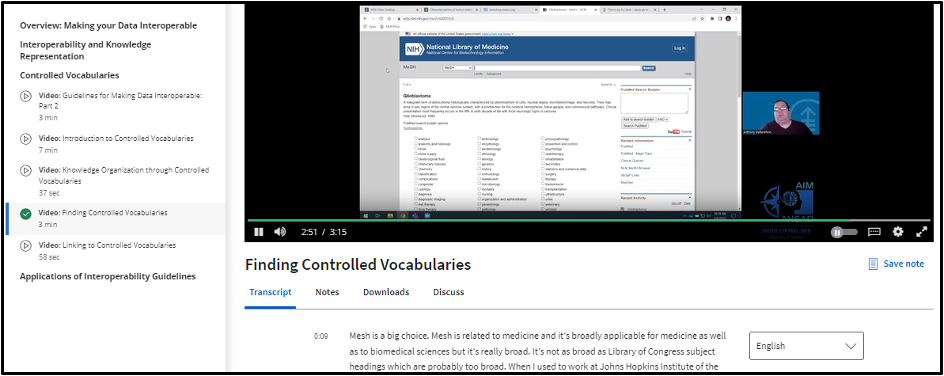
Informed by the identified training need, design precedents, and learner analysis findings, the course development team applied these insights to design the course content scope and instructional strategy. The team first developed and piloted an in-person version of the course in June 2022, and an online, on-demand version was developed and offered through Coursera the following year. Considering the contextual need to connect FAIR-based applications to the appropriate communities of practice, the course provided obesity health disparities research implications, such as using an example dataset from a study on the impacts of obesity and weight loss for hands-on practice activities. Figure 2 provides an example learning activity that used the obesity and weight loss dataset. This activity also incorporated technical skills relating to searching for controlled vocabularies with keywords in the National Library of Medicine MeSH (Medical Subject Headings). Given the target learners’ preference for visual learning methods, video vignettes were developed to correspond with the activity. The videos discuss theoretical concepts and provide examples from practice. Videos corresponding to the activity featured in Figure 2 introduce controlled vocabularies and explain how to find and link to controlled vocabularies (see Figure 3).
Figure 2
Example Learning Activity Using Obesity and Weight Loss Dataset
Learning Activity: Using Controlled Vocabularies Objectives: ● Learners will create metadata that includes FAIR vocabularies. ● Learners will find controlled vocabularies associated with terms in their fields of study. Instructions: Using the example dataset from a study on the impacts of obesity and weight loss or your dataset, write four or more keywords to describe it. Search for controlled vocabularies related to your keywords in the National Library of Medicine MeSH (Medical Subject Headings). Note: If you are using the example dataset, you can explore the keywords and MeSH terms in these articles: ● "Substitution of sugar-sweetened beverage with other beverage alternatives..." ● "Substituting sugar-sweetened beverage with water or milk..." ● "Associations between sugar intake from different food sources..." Optional: Practice working with a data repository (such as the Texas Data Repository) and create an entry for your dataset. Edit the metadata fields of key terms and top classification to include controlled vocabularies. |
Figure 3
Video Vignette of Data Management Expert
With the target learner base having minimal prior familiarity with the principles of FAIR, contextualizing concepts were incorporated into the introductory module. These concepts included explanations about the circumstances that gave rise to the development of the FAIR principles, the link between data reproducibility and scientific discovery, and the role of researchers in the data ecosystem. To support the building of the necessary background knowledge for learners to understand the rationale for implementing FAIR into their practices, foundational concepts of data reproducibility, open science, and data management were explained. Essential vocabulary terms associated with the content, such as metadata, persistent identifiers, and controlled vocabularies, were defined when first used in the modules and then curated into a complete glossary reference.
To address the target learners' preferences for interactive activities and group-based assessments, hands-on and collaborative activities that situated concepts within real-world scenarios were designed for the course. Activities included group discussions, Think-Pair-Share, sorting, concept mapping, and exploratory checklists (see Figure 4). The activities were designed at varying levels of thinking (e.g., Bloom’s taxonomy), from information recall and comprehension to implementation and evaluation (Adams, 2015). Learner-to-learner collaboration was supported through instructional technologies such as cloud-based editable document activity scaffolds.
Figure 4
Example Exploratory Checklist Learning Activity
Objective: ● Learners will create detailed provenance for a given dataset. Instructions:
|
Checklist items | Mark “X” if found in the data info page |
| Metadata includes general information such as data title, PI contact and affiliation, collaborators, date of collection, and geographic location. |
|
| Metadata provides methodological information such as data collection and processing methods. |
|
| Metadata provides an overview of data and files, such as file names, the date of file creation, and whether data is used in raw or transformed form. |
|
| Files are saved in standard formats, e.g., CSV for tabular data. |
|
| Metadata provides data-specific information such as variables, units of measurement, and code definitions. |
|
| The repository has assigned a license to the dataset. |
|
| The repository has allowed the assigning of access levels to the dataset, e.g., open, restricted, or embargoed. |
|
| Metadata includes suggestions for citation. |
|
| Metadata includes publication details. |
|
| Metadata conforms to community standards. |
|
Suggested starter texts for articulating applications of FAIR in different portions of a data management plan were embedded into the course to enable learners to more readily implement the concepts learned into their scholarly projects (Figure 5).
Figure 5
Suggested Data Availability Starter Text for Learners

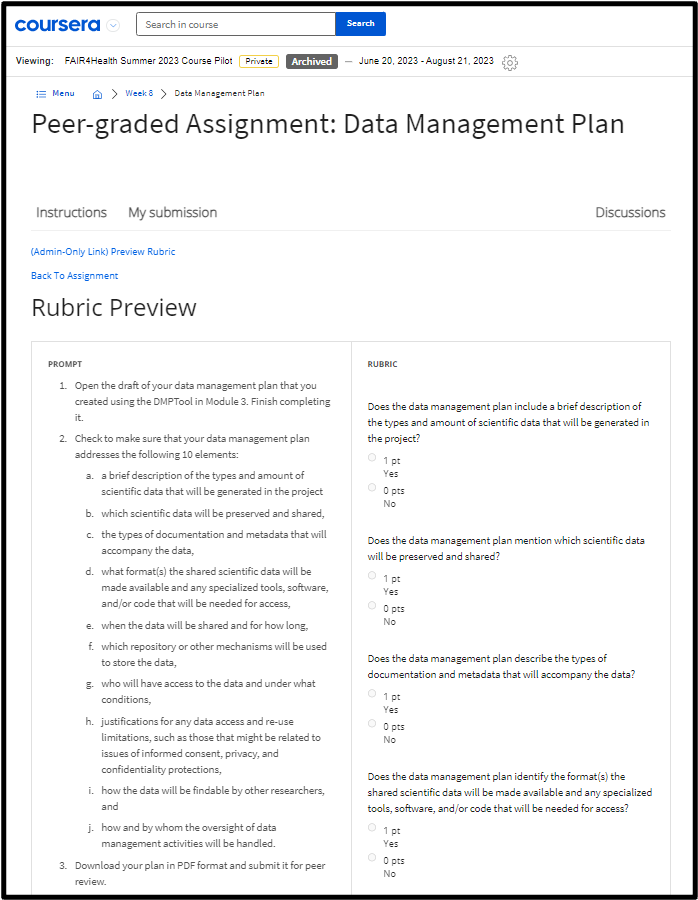
The team recognized that a range of assessment items would be needed, from recall/recognition multiple-choice items to evaluative/demonstrative authentic tasks. The activities served as formative assessments, providing opportunities for feedback and reflection on learning progress within each module. In the online version of the course, closed-response, auto-graded quizzes were created to serve as knowledge checks at the end of each module. A culminating activity of developing a data management plan incorporating FAIR principles addressed higher levels of thinking and application. The assessment was trialed as an instructor-reviewed assignment initially in-person, and then a peer-graded version was developed for online, on-demand with the aim that it could guide learners to support their classmates through review and feedback (see Figure 6). In both versions, learners needed additional time to complete the assignment than what was planned in the course, and the timeliness of feedback on their work was not optimal. Future iterations could explore its use as a scaffold for discussion of the learner’s data management plan within the broader research training and mentorship program.
Figure 6
Culminating Peer-review Assessment of Data Management Plan
The data management course described in this article focuses on applications of FAIR principles in obesity health disparities research. It aims to expand participant awareness of open science, close skill gaps in FAIR-grounded research data management practices, situate participant implementation of FAIR within their associated obesity health disparities community of practice, and improve participant skill in writing FAIR-informed data management plans as part of external funding applications. Participant demographics in the learner analysis study reflect the context of this project being situated within the OHD-PRIDE research training and mentorship program for early-career faculty and post-doctoral fellows from underrepresented groups in biomedical, behavioral, and social sciences fields, and these demographic variables minimally impacted design decisions for the curricular planning. Additionally, though learners were asked about their learning preferences prior to the development of the course, the team found in the piloting of the program that presenting course concepts through multiple modalities, including visual presentations, videos, text-based guides and templates, and exploratory learning experiences provided representations of the concepts and skills in supportive ways. The training design incorporates a single example dataset for hands-on practice activities to contextualize learner applications of the course content. The course's in-person and online, on-demand versions offer instructional format flexibility, and developing both versions met the expected deliverables of our design project.
The continued expansion of open science efforts and external funder expectations for incorporating data management plans in grant proposals will likely further fuel the need for educational programming in this area. A future iteration could merge the in-person and online formats to create a blended version, which may utilize the online content delivery as pre-class work and maximize the in-person training time for interactive learning activities. The incorporation of game-based assessments could also be explored further. Applying gamification elements would involve the need for incremental assessment points. For example, adding embedded questions in the videos could provide game-based point opportunities, foster retrieval practice, and support learner motivation and engagement (Hopkins et al., 2016).
In sum, the design team found the front-end analysis insights helpful in guiding design decisions about delivery format, scope of content, and activity structure for a data management course. Exploring design precedents spurred ideas about how the technical FAIR content could be organized into a formal instructional experience. Gathering input from target learners in the design's initial phase confirmed the course's instructional need. It also enabled the design team to understand target learner views about the proposed course aspects. The resulting course reflected proactive responses to the front-end analysis insights as the learning needs of the early-career biomedical researchers were acknowledged and addressed in teaching conceptual knowledge and relevant applied skills in FAIR principles for data management. While the course was piloted as a standalone professional development that introduces FAIR-grounded concepts and skills, future iterations could utilize the mentorship affordances of a broader research training and mentorship program, such as OHD-PRIDE, to provide extended support of skills application into the development of grant proposal data management plans.
Section 1: Demographics
Section 2: Awareness of FAIR Principles
Section 3: Learning Preferences
Research reported in this publication was funded, in part, by the National Institutes of Health (NIH) Agreement No. 1OT2OD032581-01 and the National Heart, Lung, and Blood Institute (NHLBI) of the NIH under Award Numbers R25HL126145 and R25HL126145-08S1. The content is solely the authors' responsibility and should not be interpreted as representing the official policies of the NIH or NHLBI, expressed or implied.
The authors would like to acknowledge the Obesity Health Disparities PRIDE research training and mentoring program partnership among the University of Houston, the University of California, Los Angeles (UCLA), Johns Hopkins University, and the University of Texas Southwestern for their contributions to the curriculum. The authors also thank Elizabeth Heitman, Ph.D., Haleh Aghajani, Ph.D., MSc; Anthony Dellureficio, MLS, MSc; Ramkiran Gouripeddi, MBBS, MS; and Katherine Sward, Ph.D., RN, FAAN for their review and guidance during the curriculum conceptualization and Daniel Burgos, Gione-Paul Comeaux, and Khy-Lan Patton for their contributions to the online instructional materials.